COMPAiSS does not allow AI to generate a response unless it is authorized in advance against institution-approved sources. An AI system engineered for regulated environments where accuracy, authority, and governance are non-negotiable.
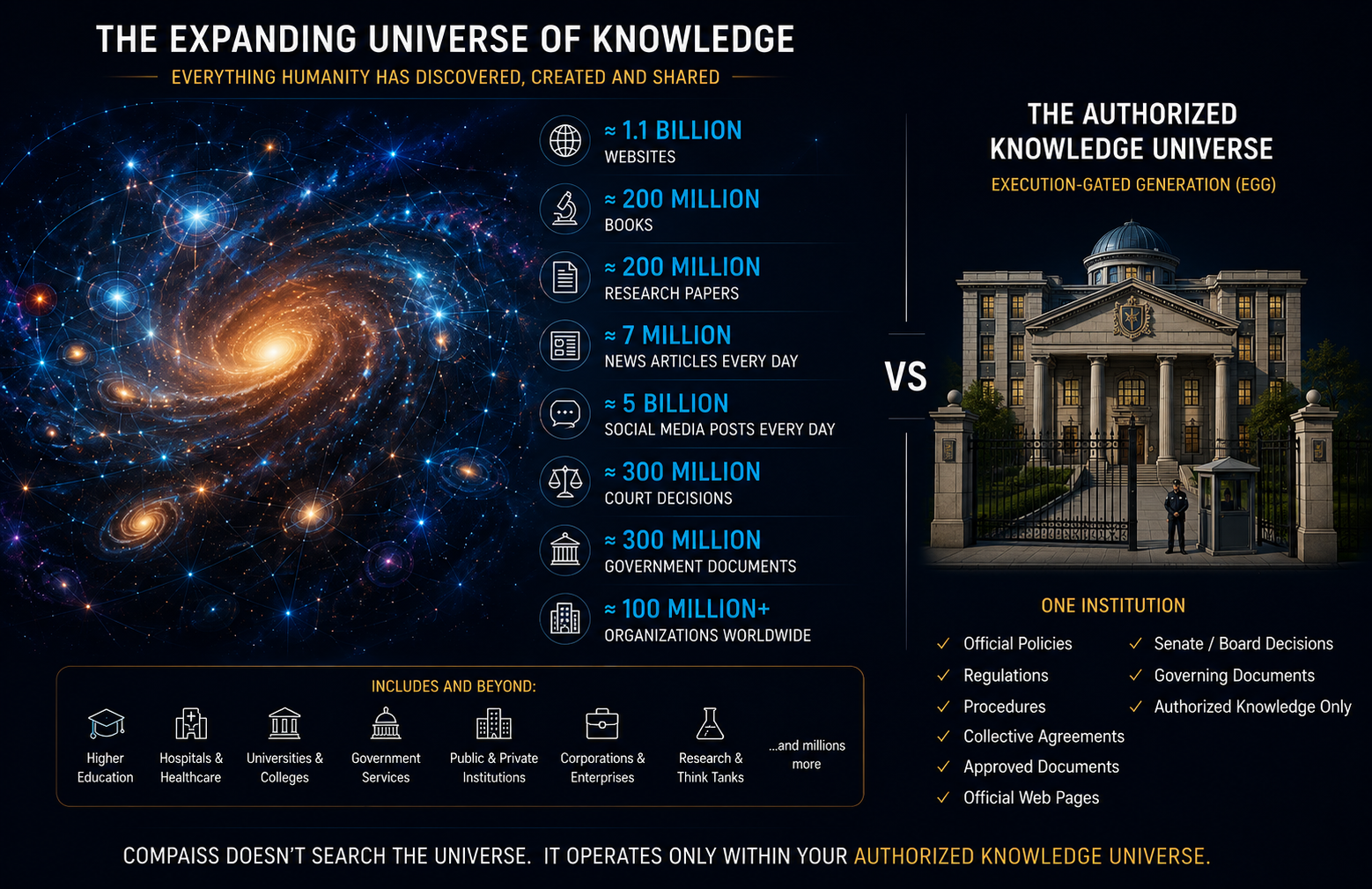
As AI systems gain access to more knowledge and become more capable, they actually become less suitable for regulated institutions, not more.
The reason is specific. When a student asks about an academic standing policy, a patient asks about a hospital's admission procedures, or a citizen asks about a benefit they may be entitled to, a general-purpose AI doesn't search only that institution's policies or only its authorized pages. It draws on billions of pieces of training data -- policies from other universities, regulations from other jurisdictions, procedures from other hospitals and governments -- and blends that information into an answer that sounds authoritative but may have nothing to do with what your institution actually says.
This is not a bug. It is how these systems are designed to work. The broader the training data, the more capable the AI, and the more opportunities there are for information from the wrong institution, the wrong jurisdiction, or the wrong year to find its way into the answer. For universities, hospitals, governments, and professional regulators, that noise is not an inconvenience. It is a governance failure.
A more capable AI doesn't make fewer mistakes of this kind. It makes mistakes that sound more convincing and are therefore much harder to detect. Waiting for future AI models to solve this problem is not a strategy. It compounds the risk.
COMPAiSS does not rely on AI to draw on billions of pieces of training data to answer your question. Instead, it first checks whether the question can be answered exclusively from your institution's authorized sources before the AI is permitted to generate a response. If the answer cannot be supported by approved institutional sources, the AI does not attempt to answer, redirecting the user to the institution.
The universe of knowledge is vast. COMPAiSS operates only within yours.

Not a configuration setting. Not a policy layer. A structural property of the architecture. The model cannot run until an external authorization check says it may.

Much of today's AI safety and hallucination research focuses on determining whether a generated answer is essentially correct. Different approaches attempt to identify uncertainty, detect hallucinations, or recognize out-of-scope questions.
COMPAiSS addresses a different governance priority. For regulated institutions, correctness and institutional authority are not the same thing. An answer may be confident, factually accurate, and still draw on information outside the sources users assume are governing the response. Origin matters as much as accuracy.
COMPAiSS is therefore not designed to provide answers that are essentially correct. Its purpose is to establish trust that every answer is derived exclusively from authorized institutional sources.
An unauthorized truth is just as dangerous as a hallucinated lie.
- What COMPAiSS Does
- Why Institutions Choose COMPAiSS
- How the Architecture Works
- The Structural Problem with AI Today
- Where Accuracy Is Not Optional
- COMPAiSS: The Structural Solution
- COMPAiSS vs. Enterprise AI
- Not RAG. Not General-Purpose. Not a FAQ Bot.
- Cost Savings by Design
- The Contrast with Enterprise AI Assistants
- Multilingual Governance
- For Consulting Firms and System Integrators
- Built for Institutional Procurement
- Institutional Accountability and Control
- Explore This Architecture
- Technical Documentation
- About COMPAiSS
What COMPAiSS Does
Turning complex institutional web ecosystems into accurate, authoritative, multilingual AI responses.
Websites for regulated institutions contain thousands of pages of information - policies, procedures, rules, and support resources - typically distributed across multiple departments, administrative offices, and service units. For most users, navigating these opaque websites to find the right answer quickly is a daunting proposition.
Universities, government service departments, hospitals, and professional regulators all face the same challenge: the information exists, but it is spread across hundreds or thousands of webpages and policy documents, each governed by different offices and updated on different schedules.
COMPAiSS solves this problem for institutions that have an obligation to provide clear, accurate, and authoritative information - delivered in any language the user prefers - without generating responses that go beyond what the institution has actually authorized.
Why Institutions Choose COMPAiSS - Governance-First
Eight outcomes that no Generation-First AI system can match by architecture.
Each of these properties is architectural - not a policy setting, not a configuration option, not a dashboard control. They are structural properties of the execution-gated generation model that cannot be accidentally disabled.
How the Architecture Works
Execution-gated generation - the AI will not answer questions it is not authorized to answer.
At its core, COMPAiSS is built on an execution-gated generation architecture. If authorization fails, the primary institutional reasoning model does not execute or allocate primary inference resources.
By controlling whether AI reasoning happens at all, COMPAiSS enforces institutional authority structurally, rather than relying on post-generation filtering or correction.
COMPAiSS employs defense-in-depth controls: authorization gating prevents unauthorized primary model execution, instruction-based constraints guide behavior during authorized inference, and post-generation validation ensures URL compliance with institutional sources.
The greenlist and parsing architecture do more than control scope - they control what the model receives as its epistemic environment. When the model receives content only from pre-parsed, institutionally authorized pages and documents, the surface area for misinterpretation is dramatically smaller than in a RAG system reasoning over a broad, unstructured corpus.
The precise claim: COMPAiSS eliminates scope-violation hallucinations by design, and materially reduces generation-quality risks within authorized scope through structured parsing and tightly bounded inference contexts.
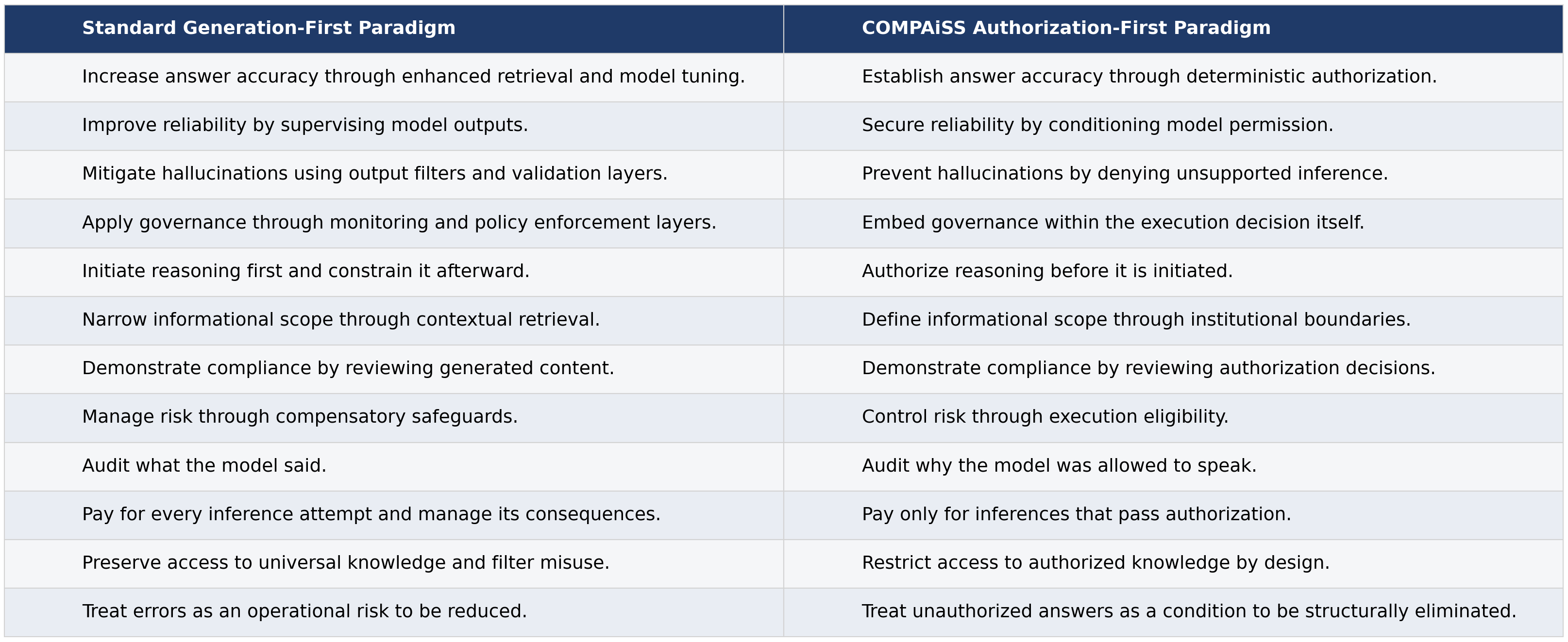
Figure 1 - Standard RAG Architecture
Illustrates how conventional AI and RAG systems operate with model inference active from the start, relying on retrieval and post-generation controls to manage risk after an answer has been produced.
Figure 2 - COMPAiSS Architecture
Shows COMPAiSS's execution-gated design, where authorization and scope validation occur before any model inference, and unsupported questions prevent the AI from running at all.
The Structural Problem with AI Systems Today
Why generation-first AI creates risks that disclaimers cannot fix.
As a direct consequence of complex institutional web ecosystems, many users turn to consumer-based AI systems (ChatGPT, Copilot, Gemini, and similar tools) to obtain fast, clear answers to institution-specific questions.
But consumer AI models are designed to generate responses by default. They optimize for broad usefulness across a vast training base. When these systems are applied to narrow, institution-specific questions, errors, hallucinations, and references to non-authoritative or external sources are a predictable byproduct of that design.
The AI industry readily acknowledges these facts - incorrect or unsupported answers are generally treated as expected outcomes to be managed rather than failures to be prevented. In regulated institutional environments, however, this approach introduces risks that are difficult - if not impossible - to fully mitigate after an answer has already been delivered.
There are also strong economic incentives to preserve this generation-first model. Managing risk after answers are produced enables entire ecosystems of enterprise features - monitoring tools, compliance dashboards, moderation layers, human review workflows, and governance add-ons - that are costly to build, costly to operate, and highly profitable to sell. These measures may reduce exposure, but they do not change the underlying architecture or eliminate the root causes of hallucinations.
Independent Evidence
A 2025 global study conducted by KPMG and the University of Melbourne surveyed more than 48,000 people across 47 countries and found that AI adoption is accelerating while trust, governance, and oversight challenges remain significant. The study reported that 66% of respondents use AI regularly, yet only 46% are willing to trust AI systems, while 70% believe stronger AI regulation is needed. The researchers concluded that organizations must strengthen governance, trust, literacy, and oversight as AI deployment expands. COMPAiSS was developed specifically to address this governance gap through pre-inference authorization and execution-gated governance.
Read the KPMG / University of Melbourne Global AI Trust Study
Where Accuracy Is Not Optional
The consequences of incorrect information are not theoretical in these environments.
Universities
Universities publish policies governing admissions, academic standing, accommodations, financial aid, degree requirements, and student rights. An incorrect answer can misrepresent official policy, lead to improper decisions or appeals, and create equity and compliance issues.
Hospitals and Health Care
Hospitals operate under strict clinical, administrative, and regulatory constraints. Inaccurate information can misstate patient rights or procedures, create compliance exposure, and undermine trust in care delivery.
Government Services
Public agencies provide information that affects benefits, eligibility, obligations, and access to services. Incorrect guidance can delay or deny services, create legal exposure, and erode public trust.
Professional Regulatory Bodies
Regulatory organizations publish licensing requirements, disciplinary procedures, and professional standards. Inaccurate guidance can misrepresent statutory requirements and expose the organization to legal challenge.
Colleges and Polytechnics
Colleges publish structured program requirements, credential pathways, and admissions standards. Incorrect information can mislead prospective students and trigger formal complaints or appeals.
Municipal Governments
Municipalities publish permit procedures, zoning regulations, and licensing rules. Incorrect guidance can create legal liability, delay public services, and generate political accountability issues.
See how COMPAiSS differs from every major AI platform — and why that difference matters for regulated institutions.
Read the competitive landscape analysis →COMPAiSS: The Structural Solution to Systemic AI Failure
Authorization before inference - not filtering after it.
Instead of generating an answer by default and attempting to manage risk afterward, COMPAiSS evaluates each question for institutional authorization before primary model inference is permitted to occur.
When a question is asked, the system first determines whether the question falls within an institution's defined scope, whether authoritative, institution-approved material exists to support an answer, and whether producing an answer would be responsible and defensible. The AI model is only allowed to provide an answer when those conditions are met.
This means COMPAiSS does not rely on disclaimers, confidence scores, post-answer filtering, or human review to retrofit compliance after an answer has already been produced. Unsupported or out-of-scope questions are prevented from triggering primary institutional model execution in the first place.
When a question is clearly institution-specific and authoritative information exists within approved sources, COMPAiSS produces a clear answer grounded exclusively in that institution's authorized materials - not inferred from the broader universe of unrelated organizations or jurisdictions. When a question cannot be supported, the system does not guess, generalize, fill gaps, or improvise simply to be "helpful".
By shifting decision-making ahead of AI generation, COMPAiSS removes the need for many of the costly corrective controls required by generation-first AI systems and eliminates a major class of unauthorized institutional hallucinations by design.
Not RAG. Not General-Purpose. Not a FAQ Bot.
Three common misconceptions - and why the architecture of COMPAiSS is different from all three.
Not Retrieval-Augmented Generation (RAG)
RAG systems connect an AI model to an institution's documents so it can retrieve relevant material before generating an answer. They are a genuine improvement over general-purpose AI, but they remain generation-first systems. And that distinction matters more than it first appears.
Between the moment a user submits a question and the moment an answer appears, a modern RAG system executes a sequence of AI models. Each model performs probabilistic inference — estimating meaning, similarity, relevance, or importance — and each prediction shapes what evidence ultimately reaches the language model. By the time the LLM begins generating text, multiple AI-driven inference steps have already determined what information it will, and will not, see. There is not one AI decision in that process. There are many.
| Stage | Where error enters |
|---|---|
| Query interpretation - AI predicts what the user intended | Ambiguous phrasing, jargon, or multilingual input can shift meaning before retrieval begins |
| Embedding generation - AI predicts the mathematical representation of meaning | Conceptually related but institutionally distinct topics can occupy similar positions in vector space |
| Vector search - AI predicts which stored content is semantically similar | Relevant material that was never indexed, chunked inconsistently, or embedded poorly will not be retrieved |
| Candidate retrieval - AI predicts which documents are most relevant | The correct document may rank below an incorrect one that happens to share surface vocabulary |
| Chunk scoring and re-ranking - AI predicts which evidence is most important | Chunk scores are relevance scores, not truth scores. The highest-scoring passage is the one that matches the query best, not necessarily the one that is authoritative |
| Context assembly - AI predicts which evidence should be presented to the LLM | Critical qualifications, exceptions, or policy nuances may be omitted if they appear in a lower-ranked chunk |
| Generation - AI predicts the next tokens that form the final response | The model fills gaps, resolves contradictions, and makes inferences, often without signalling that it is doing so |
Every stage in this pipeline relies on probabilistic AI inference. Improvements to embeddings, retrieval algorithms, or ranking models can improve individual predictions, but they do not eliminate the underlying dependence on learned statistical estimation. By the time the language model begins generating an answer, multiple AI models have already determined what evidence it will — and will not — see. The architecture therefore remains fundamentally generation-first: retrieval identifies what is probably most relevant, and the language model generates from that probabilistic evidence.
Independent evaluations of leading enterprise legal and retrieval-augmented AI systems continue to document residual hallucination and accuracy errors despite sophisticated retrieval architectures. These are not implementation failures. They are predictable consequences of generation-first architecture operating under retrieval uncertainty.
Supporting Evidence
Peer-reviewed testing of a leading enterprise legal AI platform found hallucination rates of 17 to 33 percent in real-world legal research tasks. Independent research has documented residual hallucination rates of approximately 6 percent even under optimal RAG conditions. Full citations are available in the Empirical Hallucination Rates report (PDF).
COMPAiSS is not a better RAG system. It is a different kind of system, one that asks a question RAG never asks: should the AI be permitted to answer this at all?
↓
Retrieve probable information
↓
Generate answer
↓
Manage residual errors after delivery
↓
Is this authorized? If no, stop.
↓
Discover authorized sources
↓
Parse and verify source content
↓
Evidence available? If no, stop.
↓
Generate answer from verified evidence
The difference is not that COMPAiSS retrieves better. It is that COMPAiSS determines whether inference should occur at all, and stops before generation when it should not. RAG systems try to improve what the model receives. COMPAiSS controls whether the model runs.
Not a General-Purpose AI System
General-purpose AI systems are designed to answer questions about anything. Their value lies in breadth - the ability to move freely across domains, institutions, and jurisdictions without predefined boundaries. COMPAiSS is intentionally built for institutional specificity. Its purpose is not to approximate an answer from general knowledge, but to reflect only what a particular institution has actually authorized as its official position, policy, or guidance - and only then release the AI to answer the question.
In short: general-purpose AI optimizes for how much it can answer. COMPAiSS optimizes for when it is appropriate to answer about your institution - and when it is not.
Not a FAQ Bot or Scripted Chatbot
FAQ systems are built around predefined questions and fixed answers, requiring users to frame their questions within those limits. They break down when questions exceed those limits or require context, judgment, or interpretation of institutional rules. COMPAiSS does not rely on scripts. Each question is evaluated on its own terms, drawing from relevant institutional information to provide clear, detailed, and nuanced answers aligned with what users are actually seeking.
Cost Savings by Design
The cost difference between COMPAiSS and conventional enterprise AI is structural, not marginal.
For institutions managing approximately 100,000 AI-assisted queries annually, conventional RAG deployments typically incur total annual operating costs between $90,000 and $200,000, driven by three compounding cost drivers: inference waste, persistent RAG infrastructure, and compensatory governance. A COMPAiSS deployment addressing the same workload operates at approximately $15,000 to $30,000 per year - because all three of those cost drivers are eliminated by architecture, not managed after the fact.
Approximately 40% of queries in a typical institutional deployment are denied inference entirely. Those users receive a high-value safe failure response - direct links to authoritative institutional policies - at zero to marginal compute cost.
Lower cost does not imply lower accuracy. Hallucinations require active inference. By preventing inference for unauthorized queries, COMPAiSS removes the structural conditions under which fabrication occurs - not as a downstream filter, but as an architectural property.
The Contrast with Enterprise AI Assistants
A structural difference, not a superficial one.
Systems like Microsoft 365 Copilot are designed to operate across an organization's entire digital environment: emails, documents, Teams conversations, SharePoint repositories, and calendar data. When a multilingual user submits a question, the system translates that query and then retrieves across whatever content happens to be indexed - which may include outdated policy drafts, informal communications, or documents from unrelated departments that happen to contain matching keywords.
This is not a configuration failure. It is an architectural consequence of designing a system for breadth across an entire organizational corpus rather than for authority within a defined institutional scope.
COMPAiSS separates these functions entirely. Translation normalizes the question into a working language. Authorization determines whether the institution has approved materials to support an answer. Inference occurs only if both conditions are satisfied, drawing exclusively from institution-approved sources.
This means a student asking about academic standing in Mandarin, French, or Arabic receives the same institutionally authorized answer as a student asking in English - not an approximation shaped by translation artifacts or corpus noise. For institutions with obligations to serve multilingual populations equitably, this distinction is not incidental. It is the difference between a system that is consistent by architecture and one that is consistent only when conditions happen to align.
Keeping Meaning Consistent Across Translations
Separating language from meaning at the architectural level.
Consumer-based AI systems often translate a user's question as part of how they search for information. In many RAG-based systems, this translation step is intertwined with retrieval and reasoning. As a result, small differences in phrasing can influence which documents are retrieved, how passages are interpreted, and what the system ultimately emphasizes in its response.
COMPAiSS avoids this problem by separating language from meaning at the architectural level. When a question is submitted in a non-English language, it is first translated into English as a preprocessing step outside the institutional authorization framework. Translation does not retrieve documents, interpret policy, apply institutional rules, or generate answers.
Once translated, the question is evaluated for institutional scope and authorization before any primary institutional reasoning occurs. After the answer is determined, it is translated back into the user's chosen language for presentation.
By fixing meaning, scope, and authorization before generation occurs, COMPAiSS prevents the interpretive drift and cross-language inconsistency common in RAG-based systems - ensuring that institutional answers remain accurate, authoritative, and consistent regardless of language.
For Consulting Firms and System Integrators
A different architectural option for regulated clients.
Consulting firms increasingly encounter regulated clients where the standard generation-first architecture creates more governance risk than it solves. COMPAiSS offers a fundamentally different architectural option for those organizations.
Rather than improving retrieval quality or attempting to reduce hallucinations after AI generation has already begun, COMPAiSS determines whether institutional AI generation should occur at all. For organizations whose primary requirement is authoritative, institution-governed responses rather than broad enterprise knowledge discovery, execution-gated generation is a structurally different and more defensible design choice.
Enterprise RAG strategies remain appropriate where broad organizational knowledge discovery is the objective: searching across email, documents, and internal repositories. But many regulated institutional deployments have a different requirement. The objective is not to search the widest possible corpus. It is to ensure that responses are limited to institution-approved sources and that unauthorized questions never trigger institutional AI generation. Those are governance requirements. RAG improves retrieval to support generation. COMPAiSS governs whether generation occurs at all. They address fundamentally different problems.
COMPAiSS does not compete by retrieving more information. It competes by reducing the circumstances under which AI is permitted to generate institutional information in the first place.
For consulting firms, this creates a genuine opportunity: offering clients an architectural alternative rather than another optimization of the same generation-first model. COMPAiSS can reduce infrastructure complexity, shorten deployment timelines, and strengthen institutional accountability, while giving clients a governance story that is auditable, bounded, and defensible in procurement and regulatory review contexts.
COMPAiSS architecture is the subject of patent applications currently under examination in Canada and the United States.
Built for Institutional Procurement and Governance Review
Auditable, bounded, and aligned with fiduciary obligations.
Regulated institutions do not only need AI systems that perform well - they need AI systems they can document, defend, and submit for formal review. Procurement officers, audit committees, legal counsel, and government review panels increasingly require institutions to demonstrate not just that an AI system produces good outputs, but that its governance architecture is auditable, bounded, and aligned with fiduciary obligations.
COMPAiSS is designed with this requirement in mind. Because authorization decisions are deterministic and occur before inference, every interaction follows a documented, reproducible governance path. The institution controls which sources are authoritative. The institution defines the scope boundary. The system enforces both structurally, not probabilistically.
This makes COMPAiSS directly compatible with the documentation requirements of AI governance panels, institutional ethics review processes, and government procurement frameworks - including those that require institutions to demonstrate how unauthorized or out-of-scope AI responses are prevented, not merely managed.
Institutional Accountability and Control
Visibility and control over every AI-mediated answer.
Beyond preventing AI-generated errors, COMPAiSS has direct implications for institutional accountability and content governance. When institutions provide information, they implicitly promise that it is accurate, authoritative, and reliable. COMPAiSS extends that same standard into AI-mediated answers by ensuring that primary institutional responses are grounded in institution-approved sources.
COMPAiSS also supports the ongoing quality of institutional source content in two concrete ways. Regular greenlist audits verify that every approved source is live, current, and correctly indexed - identifying broken links, outdated pages, and redirect chains before they affect responses. And because COMPAiSS surfaces the questions users are actually asking, institutions gain a continuous signal about where published content is missing, ambiguous, or in need of revision. The system does not just reflect institutional content - it helps institutions keep that content authoritative.
It is important to note that COMPAiSS, like any information system, reflects the authoritative materials it is permitted to use. If an authorized institutional link, webpage, policy document, or official guidance is outdated or requires revision, that limitation applies equally to any AI system, search tool, or human process relying on the same source. COMPAiSS does not reinterpret or supplement institutional content; it reflects what the institution itself has authorized.
The difference lies in visibility and control. By restricting answers to institution-approved sources and preventing unsupported inference, COMPAiSS makes gaps or inconsistencies explicit and correctable rather than obscuring them through generalized or speculative responses.
Regulated institutions deserve AI systems that respect their obligations - not ones that bypass them to be "helpful". COMPAiSS is designed for institutional environments where accuracy, authority, and governance are non-negotiable.
When institutional sources are incomplete or outdated, COMPAiSS reflects that honestly rather than fabricating an answer. And because the system surfaces what users are asking, institutions can identify and correct content gaps systematically - closing the loop between AI performance and institutional information quality. Full details on greenlist auditing and source maintenance are available on the Greenlist Control and Source Auditing section.
Explore This Architecture
Active deployments across Canadian institutional environments.
COMPAiSS is currently in active beta testing pilot deployments across five Canadian institutional environments, including research-intensive universities and a federal public service context, with two additional institutional pilots currently under review.
A federal-scale public service demonstration environment has also been developed to validate execution-gated generation in high-volume constituent service contexts, reflecting organizational environments that manage tens of millions of citizen interactions annually across telephone, in-person, and digital channels.
The system has been shaped through direct institutional governance experience and is currently being evaluated in registrarial and student services domains where policy accuracy and institutional authority are critical.
For institutional evaluation or technology partnership inquiries: [email protected]
New: Architectural Investigation
We asked Copilot and Gemini to analyze the architectural differences between itself and COMPAiSS. After sustained analytical engagement with the evidence, it arrived at a conclusion its initial framing had explicitly resisted.
Regulatory Compliance Comparison
This comparative assessment evaluates how leading enterprise AI platforms align with emerging Canadian and European AI governance frameworks. It examines explainability, authorization, traceability, institutional accountability, and governance architecture in regulated environments.
Rather than comparing technical performance alone, the paper evaluates whether different AI architectures satisfy the governance obligations increasingly expected of universities, governments, hospitals, and other regulated institutions.
Technical Documentation and Further Reading
White papers, architecture papers, cost analyses, comparative assessments, and governance materials for institutional evaluation.
- The Road Less Travelled - Rethinking Generative AI Costs, Safety, and Trust in Regulated Institutions - Expands on the structural arguments and associated costs of post-generation controls.
- Breaking Out of the Matrix - A New Opportunity for AI Consulting Firms with Regulated Industry Clients - White paper directed at major consulting firms, presenting the empirical case for execution-gated generation as an architectural alternative to generation-first AI governance, with active deployment evidence from Service Canada, Dalhousie University, and McGill University.
- COMPAiSS White Paper - Execution-Gated AI for Regulated Institutional Environments - Foundational overview of the COMPAiSS architecture, execution-gated generation model, multilingual authorization framework, governance controls, institutional deployment strategy, and structural contrast with generation-first AI systems.
- Authorization-Controlled Institutional AI in Regulated Environments - Outlines the structural argument behind COMPAiSS and the limitations of generation-first systems.
- Hallucinations by Design - A Cross-Model Assessment of How Major AI Consulting Firms Advise Clients to Manage Generative AI Errors - Structured cross-model consensus analysis of AI consulting firm approaches to hallucination management.
About COMPAiSS
Built from direct institutional governance experience.
COMPAiSS was developed by Frank Harvey, Professor of International Relations and Senior Advisor at Dalhousie University. Over the course of his career Harvey has held senior leadership roles (including acting President, Provost and Vice-President Academic, Dean, and Department Chair) giving him direct, institutional-level experience with the governance, accountability, and compliance obligations that regulated environments actually impose on information systems.
COMPAiSS was built from that vantage point. Not as a technology solution looking for a problem, but as an architectural response to a structural failure Harvey observed directly: institutions deploying generation-first AI in environments where that architecture cannot meet their obligations.
Architecture and development were led by Harvey. Backend engineering, API integration, and deployment infrastructure were built with AI-assisted development tools, primarily GPT, Claude, Gemini, Copilot and Perplexity under Harvey's direct architectural oversight. The system is in active production and has been tested against thousands of real user queries across student, faculty, and administrative use cases in multilingual institutional environments.
COMPAiSS is actively seeking institutional evaluation partners and technology collaborators.
COMPAiSS is available for institutional evaluation. To schedule a demonstration, discuss a pilot deployment, or request governance documentation for procurement review:
Request a Demonstration →